
Маркетологи и продуктовые аналитики часто совершают одну и ту же ошибку, они оценивают аудиторию dApp по объему средств на кошельках (метрика TVL или Balance). Видят адрес с балансом в 50 ETH и сразу заносят его в категорию ценных пользователей. Это системное заблуждение.
В Web3-аналитике первичным является не текущий баланс, а источник первоначального финансирования (Funding Source). Качественный анализ поведения (User Behavior Analytics) начинается с деанонимизации связей между кошельками. Если у вас в протоколе зафиксирован всплеск из 1000 новых адресов, и проверка показывает, что все они получили свой первый газ с одного суб-аккаунта крупной биржи или через кастомный смарт-контракт миксера в течение узкого временного окна - это не органический рост. Это промышленная сибил-ферма, которая выкачивает ликвидность или имитирует активность под будущий дроп.
Для выявления таких паттернов анализируется «генезис» кошелька: таймштамп первой транзакции, адрес-донор и цепочка последующих трансферов.
Практический SQL-запрос для Dune (Dune SQL)
Этот скрипт изолирует адреса, взаимодействовавшие с вашим смарт-контрактом, и вытаскивает по каждому из них самую первую транзакцию в сети. Это позволяет мгновенно сгруппировать пользователей по типу их «донора».
-- Выявляем первоначальный источник газа для адресов, взаимодействовавших с контрактом
WITH target_users AS (
SELECT DISTINCT "from" AS user_address
FROM ethereum.transactions
WHERE "to" = c'0x88e6a0c2ddd26feeb64f039a2c41296fcb3f5640' -- Пример: пул Uniswap v3 USDC/WETH
LIMIT 500
),
genesis_transactions AS (
SELECT
t."to" AS user_address,
t."from" AS funder,
t.block_time,
ROW_NUMBER() OVER (PARTITION BY t."to" ORDER BY t.block_time ASC) as rank_index
FROM ethereum.transactions t
JOIN target_users u ON t."to" = u.user_address
)
-- Отсекаем все транзакции, кроме самой первой исторической для каждого кошелька
SELECT
g.user_address,
g.funder AS parent_address,
g.block_time AS creation_timestamp,
-- Маркируем подозрительных доноров. Адреса ниже — примеры крупных контрактов-миксеров/мостов
CASE
WHEN g.funder = c'0x12d66748a9176f0af33dfc592215a425441047f1' THEN 'Tornado.Cash (0.1 ETH)'
WHEN g.funder = c'0x47ce0c6ed5b0ce3d3a51fdb1c52dc66a7c3c2936' THEN 'Tornado.Cash (1.0 ETH)'
ELSE 'CEX Sub-account / Standard EOA'
END AS funder_classification
FROM genesis_transactions g
WHERE g.rank_index = 1
ORDER BY g.block_time DESC;
-- Запрос тяжелый из-за JOIN по всей таблице транзакций. На больших выборках используйте партиции по block_date.Сегментация аудитории: Скорость принятия решений и логика газа
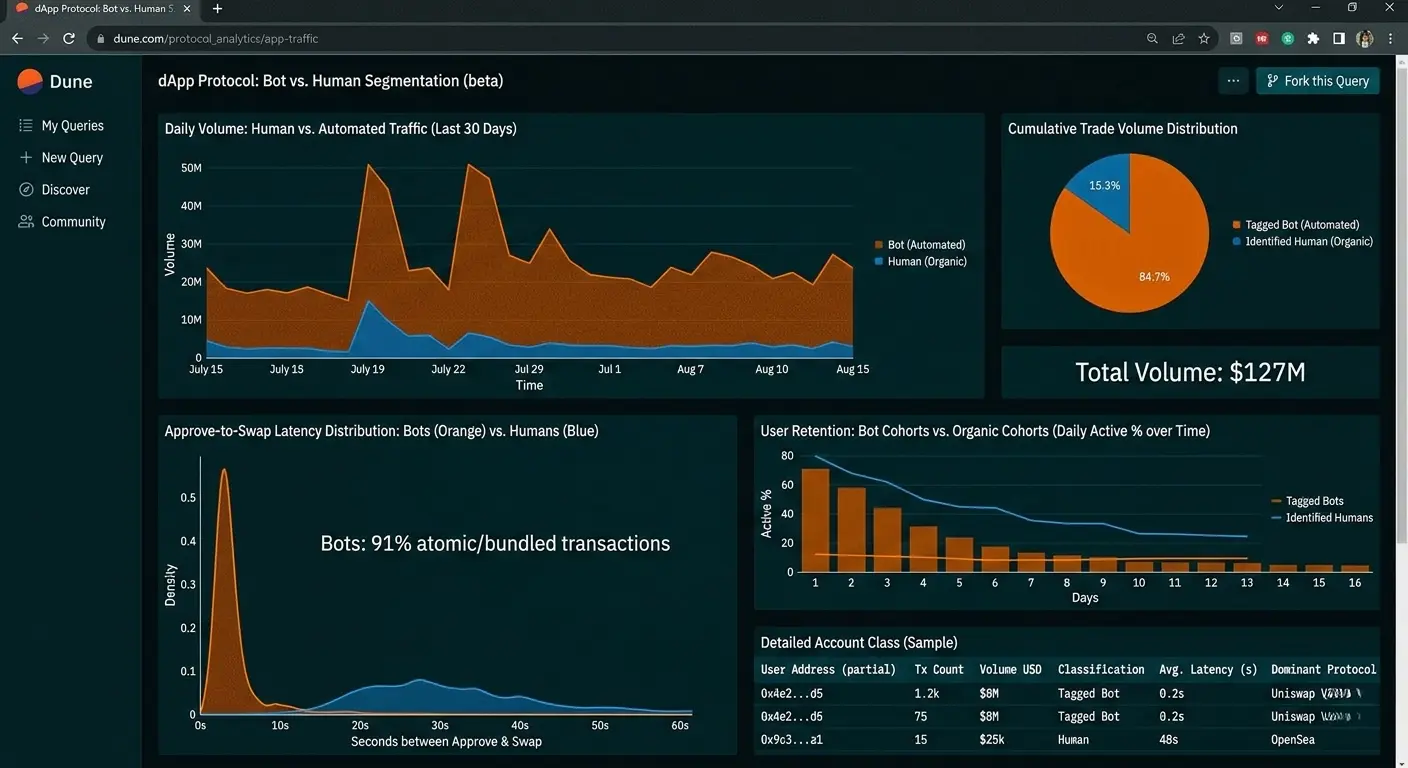
Поведенческий анализ позволяет разделить пользователей на четкие категории на основе их он-чейн дисциплины. Прямые опросы тут не работают - пользователи врут, чейн - нет.
Один из самых эффективных и редко используемых параметров сегментации - Approve-to-Swap Latency (временной лаг между разрешением на трату токенов и самим обменом).
Обычный розничный пользователь действует через стандартные интерфейсы (Metamask, Rabby). Между вызовом функции approve() и отправкой swap() у него проходит от 15 секунд до нескольких минут (пока он изучает проскальзывание, думает или отвлекается). Автоматизированные скрипты и MEV-боты подписывают эти транзакции атомарно, они уходят либо в одном блоке, либо в рамках одного Flashbots-бандла. Если дельта времени между аппрувом и непосредственным трансфером стремится к нулю, этот адрес должен размечаться как бот.
Сравнительный анализ он-чейн паттернов
| Метрика | Алгоритмический адрес (Бот/Сибил) | Розничный пользователь (Retail) | Крупный капитал (Кит) |
|---|---|---|---|
| Утилизация газа (Gas Price) | Минимально возможная (для экономии) либо экстремально высокая (для фронтраннинга) | Стандартная рыночная, часто с переплатой из-за дефолтных настроек кошелька | Рассчитанная до гвея, часто с использованием приватных RPC (Flashbots Protect) для защиты от MEV |
| Плотность взаимодействия | Цикличная. Транзакции идут ровными пачками (например, раз в 24 часа по cron-задаче) | Хаотичная. Всплески активности привязаны к инфоповодам и листингам | Низкая частота, но крупные объемы. Позиции удерживаются месяцами |
| Разнообразие токенов | 1-2 целевых актива протокола | Огромный хвост из неликвидных токенов и мемкоинов | Стабильный портфель: нативный газ (ETH/BNB), WBTC, стейблкоины |
Когортный анализ удержания (Cohort Retention) через Dune SQL
Чтобы понять, создает ли ваш продукт реальную ценность (Product-Market Fit), или вы просто сжигаете маркетинговый бюджет на привлечение одноразовых пользователей, необходим когортный анализ. Нам нужно отследить поведение юзеров, сделавших первый шаг в определенный месяц, на протяжении последующих периодов.
В Dune SQL для этого используются оконные функции и расчет разницы дат через DATE_DIFF.
-- Рассчитываем ежемесячный ретеншн пользователей для конкретного смарт-контракта
WITH user_activity AS (
SELECT
"from" AS user_address,
DATE_TRUNC('month', block_time) AS tx_month,
MIN(DATE_TRUNC('month', block_time)) OVER (PARTITION BY "from") AS cohort_month
FROM ethereum.transactions
WHERE "to" = c'0xdac17f958d2ee523a2206206994597c13d831ec7' -- Пример: контракт USDT
),
cohort_volumes AS (
-- Фиксируем стартовый размер каждой когорты
SELECT
cohort_month,
COUNT(DISTINCT user_address) AS cohort_size
FROM user_activity
GROUP BY 1
),
retention_summary AS (
-- Считаем уникальных вернувшихся пользователей по месяцам
SELECT
a.cohort_month,
DATE_DIFF('month', a.cohort_month, a.tx_month) AS period_index,
COUNT(DISTINCT a.user_address) AS active_users_count
FROM user_activity a
GROUP BY 1, 2
)
-- Формируем финальную матрицу
SELECT
r.cohort_month,
c.cohort_size,
r.period_index AS months_after_first_tx,
r.active_users_count,
ROUND(CAST(r.active_users_count AS DOUBLE) / c.cohort_size * 100, 2) AS retention_percentage
FROM retention_summary r
JOIN cohort_volumes c ON r.cohort_month = c.cohort_month
WHERE r.period_index >= 0
ORDER BY r.cohort_month ASC, r.period_index ASC;
-- Критический маркер: если retention_percentage на второй месяц (period_index = 1) падает ниже 7%, у вас проблемы с удержанием.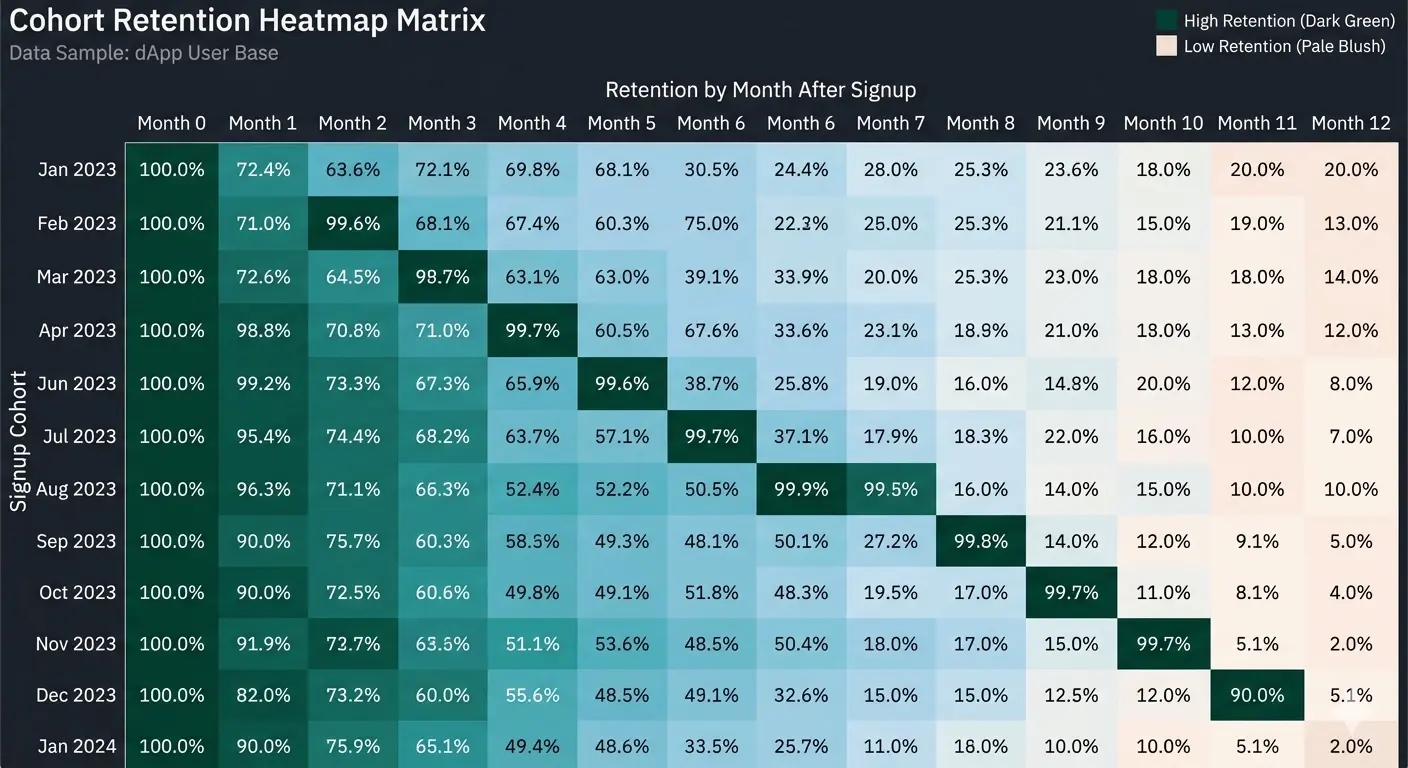
Хотя стоп, здесь есть нюанс. Если контракт системный (как USDT в примере), когорты будут огромными, и запрос может упасть по таймауту на бесплатных тирах Dune. Для кастомного dApp этот код отработает за секунды.
Скрытые эвенты: Как вытащить глубокие триггеры поведения из логов
Большинство аналитиков ограничиваются парсингом таблиц transactions или traces. Это оставляет за бортом огромный пласт данных. Профессиональный анализ требует погружения в системные логи (ethereum.logs).
Зачем это нужно? Многие современные протоколы используют мета-транзакции и абстракцию аккаунта (ERC-4337). В этом случае поле tx.from всегда будет содержать адрес релейера (сборщика транзакций), а не реального пользователя. Пытаясь анализировать стандартные транзакции, вы увидите активность трех-четырех крупных контрактов вместо тысяч уникальных юзеров.
Решение — вытаскивать данные из эвентов (Events). Например, парсить Topic 0 с хэшем события UserOperationEvent. Это позволяет определить, использует ли человек смарт-контракт кошелек (Safe, Argent), работает ли он через аппаратный стек, или взаимодействует с dApp через встроенные кошельки внутри Telegram-ботов. Понимание архитектуры кошельков вашей аудитории позволяет оптимизировать UX: рознице со смарт-кошельками не нужно объяснять, что такое газ, им нужно настраивать paymaster-контракты для оплаты комиссий в стейблкоинах.
Сквозной трекинг ликвидности: Вычисляем паттерны оттока (Lp Drain)
Когда проект запускает кампанию по стимулированию ликвидности (Liquidity Mining), набегает толпа поставщиков ликвидности (LP). Проблема в том, что значительная часть этих денег - «горячий» капитал. Они сидят в пуле ровно до тех пор, пока капает повышенный APY, а затем мгновенно извлекают средства, обрушивая глубину рынка.
Чтобы построить систему раннего предупреждения, нам нужно отслеживать не просто факт вывода ликвидности, а то, куда эти средства направляются дальше. Умные деньги и розничные инвесторы ведут себя принципиально по-разному в момент фиксации прибыли.
- Розничные адреса: Извлекают LP-токены -> Свапают их в стейблкоины или нативный газ (ETH) -> Выводят на централизованные биржи (CEX) через стандартные адреса депозитов.
- Арбитражеры и MEV-боты: Выводят ликвидность -> Мгновенно перебрасывают ее в аналогичный пул другого протокола, где APY на 0.5% выше -> Действуют в рамках одного-двух блоков.
- Институциональные пулы: Переводят средства на мультисиг-контракты или в протоколы некастодиального кредитования (Aave, Maker), используя активы в качестве залога, вместо прямой продажи.
Пишем сложный SQL-запрос для трекинга миграции LP
Давай напишем запрос, который отслеживает адреса, извлекшие ликвидность из пула (эвент Burn), и проверяет, куда эти токены ушли в течение следующих 24 часов.
-- Анализируем поведение поставщиков ликвидности после извлечения средств
WITH lp_burns AS (
SELECT
evt_tx_hash,
evt_block_time AS burn_time,
provider AS user_address,
amount0 / 1e6 AS amount_usdc, -- Предположим, токен0 это USDC
amount1 / 1e18 AS amount_weth -- Предположим, токен1 это WETH
FROM uniswap_v3_ethereum.Pair_evt_Burn
WHERE contract_address = c'0x88e6a0c2ddd26feeb64f039a2c41296fcb3f5640' -- Конкретный пул
AND evt_block_time > CURRENT_DATE - INTERVAL '30' DAY
),
subsequent_txs AS (
SELECT
b.user_address,
b.burn_time,
t.block_time AS tx_time,
t."to" AS destination_address,
ROW_NUMBER() OVER (PARTITION BY b.user_address, b.evt_tx_hash ORDER BY t.block_time ASC) as tx_order
FROM lp_burns b
JOIN ethereum.transactions t
ON t."from" = b.user_address
AND t.block_time > b.burn_time
AND t.block_time <= b.burn_time + INTERVAL '24' HOUR
)
-- Вытаскиваем самое первое действие пользователя после того, как он забрал ликвидность
SELECT
s.user_address,
s.burn_time,
s.tx_time,
s.destination_address,
-- Пытаемся идентифицировать получателя
CASE
WHEN s.destination_address = c'0x3cd751e6b0078be393132286c442345e5dc49699' THEN 'Binance Deposit'
WHEN s.destination_address = c'0x4675c7e5baafbfc4687441c22105873cd246be3a' THEN 'Hop Protocol Bridge'
WHEN s.destination_address = c'0x7a250d5630b4cf539739df2c5dacb4c659f2488d' THEN 'Uniswap V2 Router'
ELSE 'Unknown EOA / Other Protocol'
END AS next_action_destination
FROM subsequent_txs s
WHERE s.tx_order = 1
ORDER BY s.burn_time DESC;
-- Хм, тут есть тонкость. Если юзер сделал много действий в ту же секунду (бандл), подвыборка по tx_order может смазаться.Анализ "Токсичного объема" (Toxic Flow) и его влияние на метрики продукта
Для биржи или DeFi-протокола критически важно понимать качество торгового объема. Объем бывает органическим (когда пользователи меняют активы для личного использования) и токсичным (арбитраж, LVR - Loss Versus Rebalancing).
Токсичный объем генерируют боты, которые забирают ликвидность у пассивных LP в момент резкого движения цены на внешних площадках (например, на Binance). Если аналитик видит рост объемов торгов на dApp и бежит докладывать о росте популярности - он, скорее всего, ошибается. Протокол в этот момент может просто неэффективно обновлять оракулы, и его банально доят арбитражеры.
Как вычислить токсичный адрес через SQL?
Мы смотрим на метрику PnL транзакции в течение 5 блоков. Если адрес совершает свап, и в течение следующих 5 блоков цена актива изменяется в сторону, невыгодную для пула, но выгодную для этого адреса - это чистый арбитраж.
Адреса с высокой долей таких транзакций (более 80% от их общего объема) должны помечаться в аналитической базе данных тегом Arbitrage_Bot. При оценке реального удержания пользователей (Retention) их объемы нужно исключать из общей статистики, иначе вы получите искаженную картину метрик вовлеченности.
Архитектура аналитического дашборда: от сырых логов к продуктовым инсайтам
Полноценный он-чейн анализ не может строиться на разовых запросах. На практике данные агрегируются в кастомные таблицы (Spells в терминологии Dune), которые обновляются по расписанию.
Ниве представлена проверенная схема организации данных для продуктового анализа Web3-проекта.
[Сырые данные сети (Blocks, Transactions, Logs)]
│
▼
[Декодированные контракты (Events & Calls)] ──► Исключаем системный шум и сбои
│
▼
[Бизнес-логика (Таблицы Spells: Свапы, Депозиты)] ──► Фильтрация по Approve-to-Swap Latency
│
▼
[Поведенческие когорты (Конечный дашборд)] ──► Продуктовые метрики (LTV, CAC, Retention)Главный вывод для аналитика
Прекратите оценивать Web3-продукты метриками из Web2. Количество уникальных кошельков (UAW) и общий объем транзакций (Volume) легко подделываются с минимальными затратами на газ. Настоящая аналитика поведения пользователей лежит на стыке исследования их financial генеалогии (источников газа), временных лагов между системными вызовами и структуры движения капитала после взаимодействия с вашими контрактами. Чейн не врет, нужно просто уметь его спрашивать.


